计算机视觉 复习笔记
Intro
计算机视觉
研究用计算机来模拟生物外显或宏观视觉功能的科学和技术.计算机视觉系统的主要目标是用图像创建或恢复现实世界模型,然后认知现实世界.
计算机视觉中心任务就是对图象进行理解
- 对单幅图象的理解
- 对多幅图象的理解
- 对视频图象的理解
理解什么?
形状、位置、运动、类别
核心问题
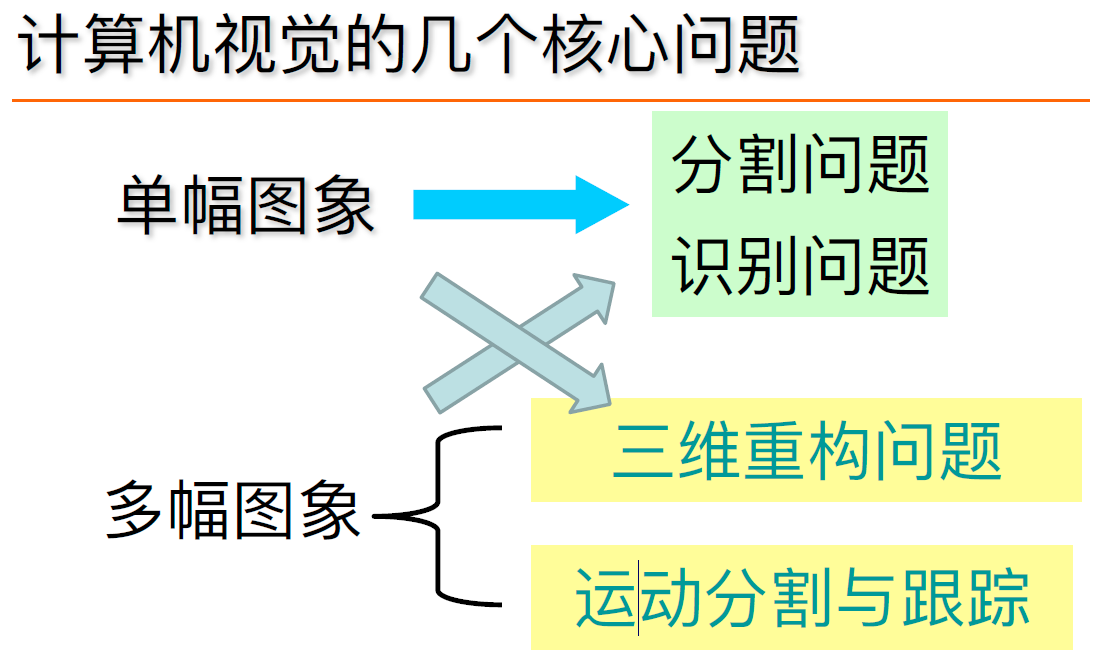
计算机视觉五大研究内容
1)输入设备 (input device) 包括成像设备和数字化设备.成象设备是指通过光学摄像机或红外、激光、超声、X射线对周围场景或物体进行探测成象,得到关于场景或物体的二维或三维数字化图像.
2)低层视觉 (low level/early) 主要是对输入的原始图像进行处理.这一过程借用了大量的图像处理技术和算法,如图像滤波、图像增强、边缘检测、纹理检测、运动检测,以便从图像中抽取诸如角点、边缘、线条、边界、⾊彩、纹理、运动等关于场景的基本特征.
3)中层视觉(middle level) 主要任务是恢复场景的深度、表面法线方向、轮廓等有关场景的2.5维信息,实现的途径有立体视觉( stereovision )、测距成像(rangefinder)、从X恢复形状(Shape from X, X = 明暗、 纹理、运动) 系统标定、系统成像模型等研究内容一般也是在这个层次上进行的.分割、拟合等
4)高层视觉(high level) 主要任务是在以物体为中心的坐标系中,在原始输入图像、图像基本特征、2.5维图的基础上,恢复物体的完整三维图,建立物体三维描述,识别物体并确定物体的位置和方向
5)体系结构(system architecture) 在高度抽象的层次上,根据系统模型而不是根据实现设计的具体例子来研究系统的结构.为了说明这一点,可以考虑建筑设计中某一时期的建筑风格(如清朝时期)和根据这一风格设计出来的具体建筑之间的区别.体系结构研究涉及一系列相关的课题:并行结构、分层结构、信息流结构、拓扑结构以及从设计到实现的途径等等.
Marr 视觉计算理论
Marr视觉计算理论立足于计算机科学,系统地概括了心理生理学、神经生理学等方面取得的所有重要成果,是视觉研究中迄今为止最为完善的视觉理论.
Marr建立的视觉计算理论,使计算机视觉研究有了一个比较明确的体系,并大大推动了计算机视觉研究的发展.人们普遍认为,计算机视觉这门学科的成与Marr的视觉理论有着密切的关系.
信息处理分析的三个层次
| 计算层 | 表示和算法层 | 实现层 |
|---|---|---|
| 计算的目的是什么?为什么这一计算是合适的?执行计算的策略是什么? | 如何实现这个计算?输入、输出的表示是什么?表示与表示之间的变换是什么? | 在物理上如何实现这些表示和算法? |
视觉表示框架的三个阶段
第一阶段(Primal Sketch):将输入的原始图像进行处理,抽取图像中诸如角点、边缘、纹理、线条、边界等基本特征,这些特征的集合称为基元图;
第二阶段(2.5D Sketch):指在以观测者为中心的坐标系中,由输入图像和基元图恢复场景可见部分的深度、法线方向、轮廓等,这些信息包含了深度信息,但不是真正的物体三维表示,因此,称为二维半图;
第三阶段(3D Model):在以物体为中心的坐标系中,由输入图像、基元图、二维半图来恢复、表示和识别三维物体。
Gestalt 理论
Gestalt理论反映了方类视觉本质的某些方面,但它对感知组织的基本原理只是一种公理性的描述(descriptive),⽽不是一种机理性的解释(explanatory)。
- Law of Proximity
- Elements that are closer together will be perceived as a coherent object
- Law of Similarity
- Elements that look similar will be perceived as part of the same form
- Law of Good Continuation
- Humans tend to continue contours whenever the elements of the pattern establish an implied direction
- Law of Closure
- Humans tend to enclose a space by completing a contour and ignoring gaps in the figure.
- Law of Prägnanz (good form)
- A stimulus will be organized into as good a figure as possible. Here, good means symmetrical, simple, and regular.
- Law of Figure/Ground
- A stimulus will be perceived as separate from it’s ground.
二值图像
二值化
Otsu流程:
- 先计算影像的直方图
- 把直方图强度大于阈值的像素分成一组,把小于阈值的像素分成另一组。
- 分别计算这两个组的变异数,并把两个组内变异数相加。
- 将0〜255当前阈值来计算组内变异数和,总和值最小的就是结果阈值。
几何特性
面积(零阶矩)
区域中心(一阶矩)
方向
– 某些形状(如圆)是没有方向的;
– 假定物体是长形的,长轴方向为物体的方向;
求方向:最小化问题
最小二乘法
伸长率
密集度
圆 > 正方形 > 长方形
形态比
区域的最小外接矩形的长与宽之比
欧拉数
亏格数 (genus)
连通分量数减去洞数
平移、旋转、放缩 不变
距离度量
metric:
d(p,q) >= 0, 当且仅当 p=q时, d(p,q)=0
d(p,q) = d(q,p)
d(p,r) <= d(p,q) + d(q,r)
- 常用距离
- 欧几里德距离(Euclidean)
- 街区距离(block)
- 棋盘距离(chess) max
- Minkowski 距离(p-norm distance)
投影计算
水平投影:计算每一列像素为1的个数。
垂直投影:计算每一行像素为1的个数。
对角线投影:从左下到右上,计算每一个对角线像素为1的个数。
连通区域标记
四联通邻点 / 路径
八联通邻点 / 路径
连通是等价关系,自反性, 对称性,传递性
连通分量: 连通像素的集合
递归算法
(1)扫描图像,找到没有标记的一个前景点(即像素值为1),分配标记L
(2)递归分配标记L给该点的邻点
(3)如果不存在没标记的点,则停⽌
(4)返回第(1)步
序贯算法
序贯算法(for 4连通)
(1)从左到右、从上到下扫描图像
(2)如果像素点值为1,则(分4种情况)
- 如果上面点和左面点有且仅有一个标记,则复制这一标记
- 如果两点有相同标记,复制这一标记
- 如果两点有不同标记,则复制上点的标记且将两个标记输⼊等价表中作为等价标记
- 否则给这一个象素点分配一新的标记并将这一标记输⼊等价表
(3)如果需要考虑更多点,则返回(2)
(4)在等价表的每一等价集中找到最低的标记
(5)扫描图像,用等价表中的最低标记取代每一标记
边界跟踪算法
(1)从左到右,从上到下扫描图像,求区域S的起始点
(2)用c表示当前边界上被跟踪的象素点,置c=s(k),记c的左邻点为b
(3)按逆时针方向记从b开始的c的8个8邻点分别为
(4)从b开始,沿逆时针方向找到第一个 ni in S
(5)置 c = s(k) = ni, b = ni-1
(6)重复步骤(3),(4),(5),直到s(k)=s(0)
形态学算子
- 膨胀 Dilate
- 腐蚀 Erode
- 开操作 Open
- 闭操作 Close
Edge Detection
基本思想:
函数导数反映图像灰度变化的显著程度。
一阶导数的局部极大值,或二阶导数的过零点。
模板 & 卷积
- 模板(Template/Kernel): A matrix represents an operator. A convolution template centers on each pixel in an image and generates new output pixels.
- 卷积(Convolution): by using the template, the new pixel value is computed by multiplying each pixel value in the neighborhood with the corresponding weight in the convolution mask and summing these products.
基于一阶导数的边缘检测
梯度
梯度方向
梯度方向为函数最大变化率方向。
用差分近似偏导数
Roberts交叉算子
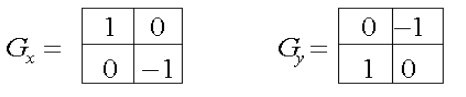
Sobel算子
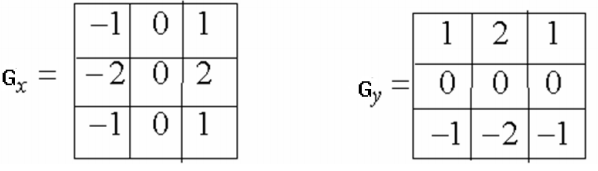
Prewitt算子
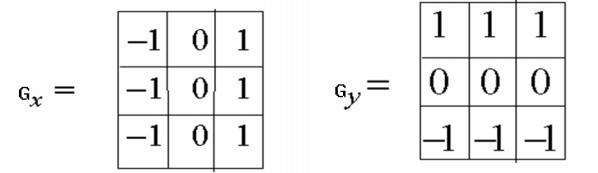
基于二阶导数的边缘检测
图像灰度二阶导数的过零点对应边缘点。
Laplacian 算子
二阶导数的二维等价形式
LoG 边缘检测
Laplacian of Guassian
- 平滑滤波器是高斯滤波器
- 采用拉普拉斯算子计算二阶导数
- 边缘检测判据是二阶导数零交叉点 并 对应一阶导数的较大峰值
- 使用线性内插方法在子像素分辨率水平上估计边缘的位置
两种等效计算方法
- 图像与高斯函数卷积,再求卷积的拉普拉斯微分
- 求高斯函数的拉普拉斯微分,再与图像卷积
墨西哥草帽算子
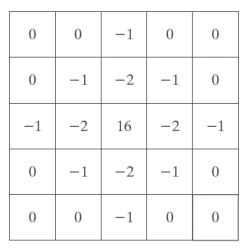
Canny 边缘检测器
算法步骤:
- 用高斯滤波器平滑图像
- 用一阶偏导有限差分计算梯度幅值和方向
- 对梯度幅值进行非极大值抑制(NMS)
- 用双阈值算法检测和连接边缘
Why 高斯滤波器?
平滑去噪和边缘检测是一对⽭盾,应用高斯函数的一阶导数,在二者之间获得最佳的平衡
非最大值抑制
去掉幅值局部变化非极大的点.
- 将梯度角离散为圆周的四个扇区之一,以便用3×3的窗作抑制运算 //TODO
- 方向角离散化:
ζ [i, j] = Sector(θ[i, j]) - 抑制,得到新幅值图:
N[i, j]= NMS(M[i, j],ζ [i, j])
How to抑制? 若M[i,j]不比沿梯度线方向上的两个相邻点幅值大,则N[i,j]=0
双阈值化
双阈值化并边缘链接
(a) 取高低两个阈值(T2, T1)作用于新幅值图N[i,j],得到两个边缘图:高阈值和低阈值边缘图。
高阈值图:N[i,j] > T2;
低阈值图:N[i,j] > T1
(b) 连接高阈值边缘图,出现断点时,在低阈值边缘图中的8邻点域搜寻边缘点。
- 阈值太低: 假边缘;
- 阈值太高: 部分轮廊丢失.
- 选用两个阈值: 更有效的阈值方案.
Local Feature
Harris Corner Detector
若 R>0(大于某一阈值),则为角点;R<0,则为边;R 绝对值很小,则为平面区域。
选取 R 得到的符合条件点的局部最大值作为结果。
Scale Invariant Detection: Summary
- Given: two images of the same scene with a large scale difference between them
- Goal: find the same interest points independently in each image
- Solution: search for maxima of suitable functions in scale and in space (over the image)
Methods:
- Harris-Laplacian [Mikolajczyk, Schmid]: maximize Laplacian over scale, Harris’ measure of corner response over the image
- SIFT [Lowe]: maximize Difference of Gaussians over scale and space
Laplacian Harris Corner
设计一个尺度不变函数,不同尺度下的图片找到的区域是相同的
- 在多尺度检测关键点
- 然后找上下不同尺度的局部最大值
- 消除低于阈值的点
Laplacian
Difference of Gaussians
SIFT Descriptor
基本步骤
- 构建尺度空间,建立图像金字塔。
- 寻找极值点(相邻的 26 个点中最大 / 最小值)
- 去除不好的特征点:使用近似的 harris corner,检测关键点的位置和尺度,并且去除边缘响应点。
- 用 16x16 的窗口放在特征点附近
- 将 16x16 分成 16 个 4x4 的窗口
- 计算窗口中每个像素的边的方向(梯度角减去 90°)
- 丢掉方向能量小的边(使用阈值)用直方图描述结果
- 将每个小窗口中的所有的方向离散成 8 个方向,一共 16x8=128 个
为什么只使用梯度信息
因为梯度信息可以表示边缘信息,并且在光照变化时有抵抗能力
如何实现旋转不变的
因为我们找的是对应位置的参考方向而非绝对方向
尺度不变的原理
因为在使用高斯模糊的不同尺度(如图像金字塔)处重新采样图像,仅当在两个尺度之间观察到最大值时才将梯度存储为描述符
Curves
Hough 变换
Hough 变换是基于投票原理的参数估计方法,是一种重要的形状检测技术
基本思想:图像中的每一点对参数组合进行表决,赢得多数票的参数组合为胜者(结果)
用极坐标来表示直线,从
步骤:
- 适当地量化参数空间 (合适的精度即可)
- 假定参数空间每一个单元都是一个累加器,把累加器初始化为 0
- 对图像空间的每一点,在其所满足的参数方程对应的累加器上加 1
- 累加器阵列最大值对应模型的参数
Fourier Transform 傅立叶变换
变换:用正弦来表示,对于二维图像而言,由以下的基图像表示:

低频与高频:亮度灰度剧烈变化的地方是高频(图像边缘和轮廓的度量),对应边缘;
变化不大的是低频(图像强度的综合度量),对应大片色块。
近处看到的是高频分量,远处观察到的是低频分量。
怎么理解拉普拉斯金字塔的每一层是带通滤波?
拉普拉斯金字塔是将图像下采样后再上采样得到的差值图像。
相减 保留细节 高通
下采样 降噪 低通
Image Pyramids
- “Gaussian” Pyramid
- “Laplacian” Pyramid
PCA
主元分析 (PCA)
用于数据集降维。
选择一个新的坐标系统进行线性降维,使得第一轴上是最大投影方向,第二轴上是第二大投影方向…… 以此类推。
Eigenface
- 预处理:根据人眼位置进行裁剪,进行灰度均衡化。
- 将二维人脸图像按一行行向量拼成一列,得到列图像;并把所有列图像拼起来,并求出平均人脸。
- 图像的协方差矩阵。
- 求协方差矩阵的特征值,以及归一化的特征向量,即为特征人脸。
识别
将两张图像都投影到人脸空间,比较投影向量的欧氏距离。
重构
将图像投影到人脸空间,通过左乘特征人脸空间矩阵恢复。
Camera Model
Thin Lenses
DOF: Depth of Field
FOV: Field of View focal length
Pinhole Camera Model
基本投影
perspective projection
projection matrix
Intrinsic Parameters

f: 焦距对应的像素
c: 图像中心与坐标原点的偏移
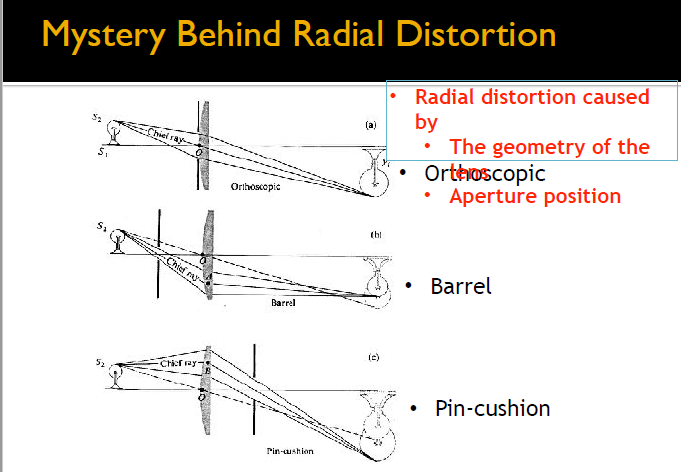
Lens Distortion
Radial Distortion
- Caused by imperfect lenses: Geometry of Lens, Aperture Position(几何性质, 光圈位置)
- Deviations are most noticeable for rays that pass through the edge of the lens
常见枕形畸变和桶型畸变:
Correcting
k1, k2, k3
Tangential Distortion
The decentering of the optical component (assembly process)
由于 CMOS 等感光元件摆放倾斜,没有平行于图像平面
越靠近中间,畸变越小
Correcting
p1, p2
Distortion Parameters
Extrinsic Parameters

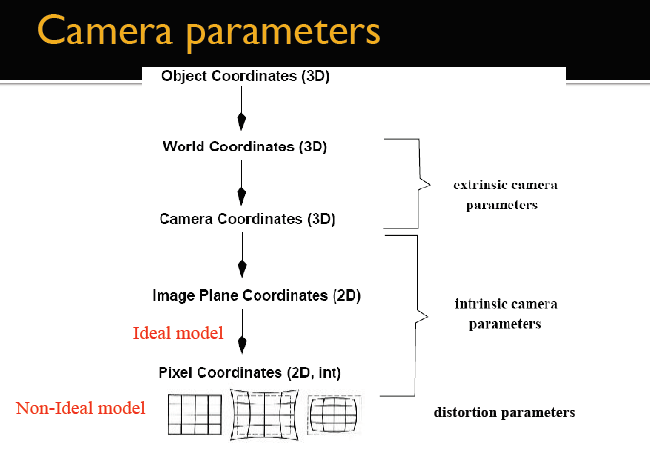
成像过程
内参,外参,畸变参数在成像各阶段中的角色(三维物体到真实图像的过程)
- 第一步是从世界坐标系转为相机坐标系,这一步是从三维点到三维点的转换,包括 R,t 等参数(相机外参)
- 第二步是从相机坐标系转为成像平面坐标系(像素坐标系),这一步是三维点到二维点的转换,包括 K 等参数(相机内参)
- 最后再用到畸变参数
Motion Estimation
Optical Flow
光流解决的是什么问题?
评估从 H 到 I 的像素运动,给出图像 H 中的一个像素,找到图像 I 中相同颜色的相近像素。解决的是像素对应问题。
光流三个基本假设是什么?
亮度恒定性 brightness constancy
空间相干性 spatial coherence
细微运动 small motion
哪些位置的光流比较可靠,为什么
纹理复杂区域,梯度比较大且方向不同,求出来的特征值比较大
推导
Camera Calibration
Given:
N correspondences b/w scene and images
Recover the camera parameters:
Distortion coefficients, intrinsic para., extrinsic para
基于 Pattern/Reference Object 的相机标定
已知:给定标定物体的 N 个角点,K 个视角(棋盘格子两个点可以得出四个等式)
求解:所有的参数。N 个点 K 个视角可以列出 2NK 个等式,会带来 6K+4 个参数。需要 2NK>6K+4.
简述其基本过程
- 获取标定物体网格的角点在坐标系的位置
- 找到图片的角点
- 根据图像空间坐标系到世界坐标系列出等式
- 求解相机参数
Two View Vision
Triangular 测量
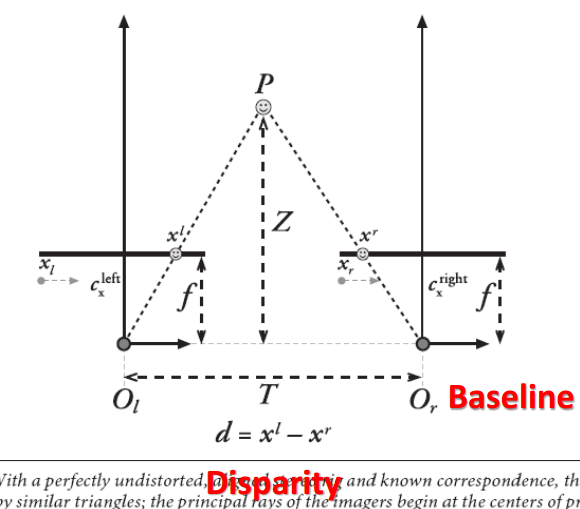
视差:
Z 的结果误差主要在分母(视差)那里。视差小的时候,视差的误差会对 Z 产生很大的影响。
T 越小,误差越小
T 越大,看到的范围越小(因为是取两眼图像的交叉部分)
How To Do Stereo
- undistortion 消除畸变影响
- rectification 校正相机位置 row-aligned
- correspondence 找到对应点 计算视差disparity
- Reprojection 三角测量->depth map
三维数据获取
Structured Lighting 结构光成像系统结构
结构光投影仪 + CCD 相机 + 深度信息重建系统
projector (one or more), CCD camera (one or more), and depth recovery system
结构光获取三维数据原理
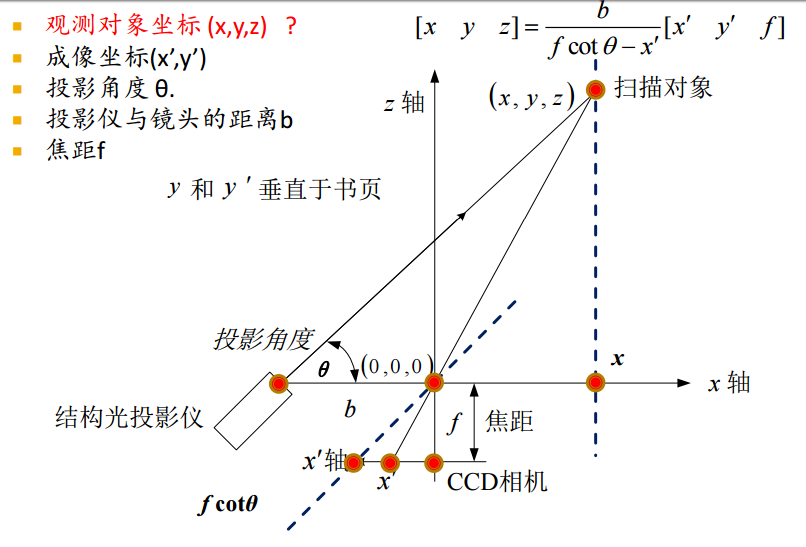
encoding
位码
3:4567
2:2367
1: 1457
ICP - Iterative Closet Point
ICP:迭代最近点方法(用于多个摄像机的配准问题,即把多个扫描结果拼接在一起形成对扫描对象的完整描述)
基本步骤:
给定两个三维点集 X 与 Y,将 Y 配准到 X:
- 建立两个扫描结果之间的对应关系
- 通过迭代获得一个仿射变换函数能够描述1中对应点之间的变换关系
- 对 Y 应用上一步求得的仿射变换,更新 Y
- 两个结果中距离最近的点作为对应点,计算对应点的距离如果大于阈值,重复23,否则停止计算
寻找F就变成了找到使Cost最小的点的搜索过程,这就是本算法称为ICP的原因。
Image Segmentation
K-means
第一步:任意选择 k 个 sift 特征点作为初始聚类质心。
第二步:对于每个 sift 特征点,计算它们与 k 个聚类质心的欧式距离,找到最小的那个聚类质心,将该特征点放入此聚类质心集合中。
第三步:对于每个聚类质心集合,用所有元素均值来更新质心。
第四步:比较更新前后聚类质心集合No points are re-assigned, 否则返回步骤 2,如果迭代次数太多聚类失败。
Pros
- Simple and fast
- easy to implement
Cons
- Need to choose K
- Sensitive to outliers
Usage
- Rarely used for pixel segmentation
Graph Cut
Input: User provides rough indication of foreground region.
Goal: Automatically provide a pixel-level segmentation.
识别 Visual Recognition
基本任务及挑战因素
基本任务大概可以分为哪几大类
图片分类
检测和定位物体/图片分割
估计语义和几何属性
对人类活动和事件进行分类
都有哪些挑战因素
视角变换
光线变化
尺度变化
物体形变
物体遮挡
背景凌乱
内部类别多样
基于词袋 (BoW) 的物体分类
图像的BoW(bag-of-words)是指什么意思?
图像中的单词被定义为一个图像块的特征向量,图像的Bow模型即图像中所有图像块的特征向量得到的直方图
基本步骤
特征提取与表示
通过训练样本聚类来建立字典 (codewords dictionary)
用字典的直方图来表达一张图像
根据 bag of words 来分类未知图像
Stitching
- Detect key points
- Build the SIFT descriptors
- Match SIFT descriptors
- Fitting the transformation
- RANSAC
- Image Blending
RANSAC
RANdom SAmple Consensus
- Approach: we want to avoid the impact of outliers, so let’s look for “inliers”, and use only those.
- Intuition: if an outlier is chosen to compute the current fit, then the resulting line won’t have much support from rest of the points.
RANSAC loop:
- Randomly select a seed group of points on which to base transformation estimate (e.g., a group of
matches) - Compute transformation from seed group
- Find inliers to this transformation
- If the number of inliers is sufficiently large, recompute least-squares estimate of transformation on
all of the inliers - Keep the transformation with the largest number of inliers
n, k, t, d
优点:是大范围模型匹配问题的一个普遍意义上的方法,且运用简单,计算快。
缺点:只能计算outliers不多的情况(投票机制可以解决outliers高的情况)
本文标题:计算机视觉 复习笔记
文章作者:Han Yang
发布时间:2018-01-16
最后更新:2022-09-06
版权声明:本博客所有文章除特别声明外,均采用 CC BY-NC-SA 3.0 CN 许可协议。转载请注明出处!
分享