操作系统 复习笔记
Intro
系统提供的接口有二类:
命令级接口,它提供键盘或鼠标等命令。
程序级接口,它提供一组系统调用System calls ,即操作系统服务,供用户程序和其它程序调用。
OS is a resource allocator
- Manages all resources
- Decides between conflicting requests for efficient and fair resource use
OS is a control program
- Controls execution of programs to prevent errors and improper use of the computer
bootstrap program is loaded at power-up or reboot
- Typically stored in ROM or EEPROM, generally known as firmware
- Initializates all aspects of system
- Loads operating system kernel and starts execution
Operating System Structures
System Calls :Programming interface to the services provided by the OS
System calls are the programming interface between processes and the OS kernel.
Why use API’s rather than system calls?( exam of my system programming)
System calls differ from platform to platform. By using a stable API, it is easier to migrate your software to different platforms.
The operating system may provide newer versions of a system call with enhanced features. The API implementation will typically also be upgraded to provide this support, so if you call the API, you’ll get it. If you make the system call directly, you won’t. (For example, code that called the Linux pthreads API for mutexes got the benefit of futexes without adding a single line of code. Had you called the system directly, that would not have happened.)
The API usually provides more useful functionality than the system call directly. If you make the system call directly, you’ll typically have to replicate the pre-call and post-call code that’s already implemented by the API. (For example the ‘fork’ API includes tons of code beyond just making the ‘fork’ system call. So does ‘select’.)
The API can support multiple versions of the operating system and detect which version it needs to use at run time. If you call the system directly, you either need to replicate this code or you can only support limited versions.
WINDOWS 启动
- ROM中POST(Power On Self-Test)代码
- BIOS/EFI(Extended Firmware Interfacte)
- MBR(Main Boot Record)
- 引导扇区(Boot sector)
- NTLDR/WinLoad
- NTOSKRNL/HAL/BOOTVID/KDCOM
- SMSS.EXE
- WinLogon.EXE
Process
进程是什么?
一个具有一定独立功能的程序在一个数据集合上的一次动态执行过程。
正在执行中的程序 a program in execution
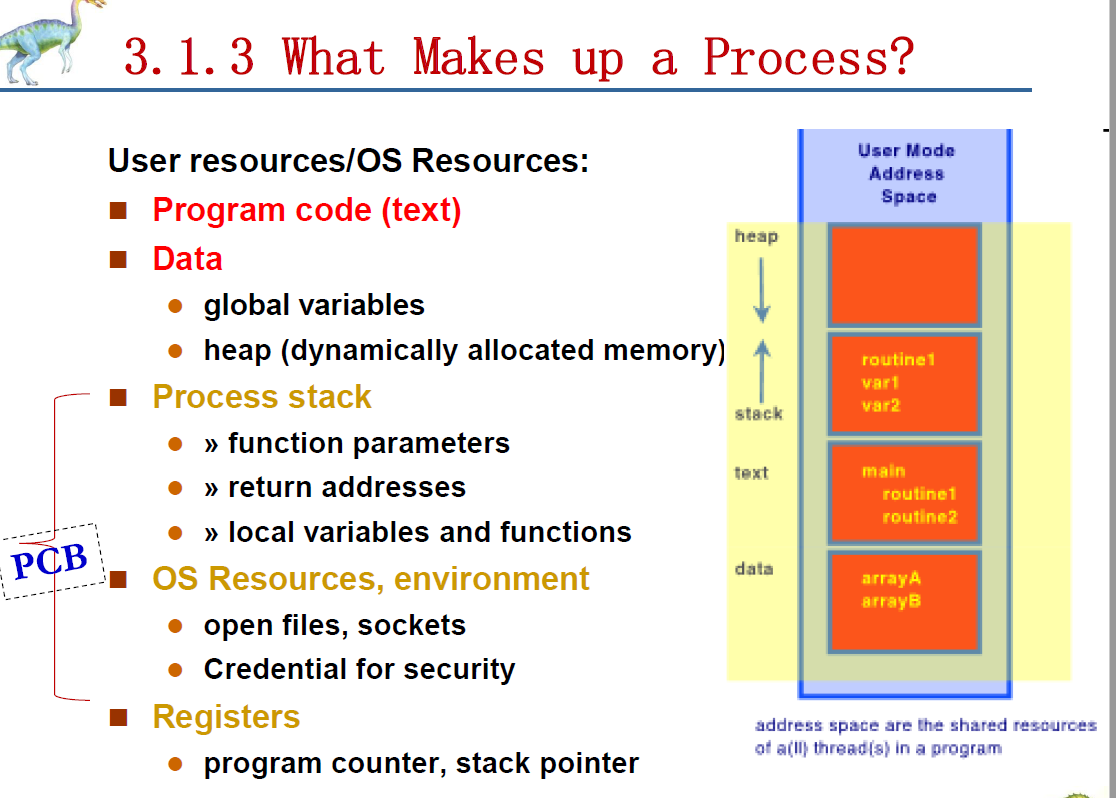
A process includes:
- Program counter (PC)
- Registers
- Data section (global data)
- Stack (temporary data)
- Heap (dynamically allocated memory
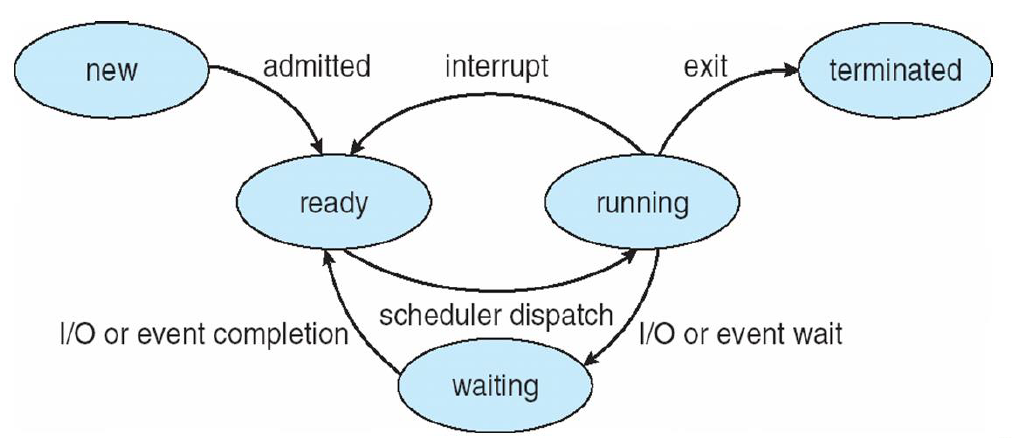
As a process executes, it changes state
- New(新): The process is being created.
- Running(运行、执行): Instructions are being executed.
- Ready(就绪): The process is waiting to be assigned to a processor (CPU).
- Waiting(等待、blocked阻塞): The process is waiting for some event to occur.
- Terminated(终止): The process has finished execution.
- Process state
- Program counter
- CPU registers
- CPU scheduling information
- Memory-management information
- Accounting information
- File management
- I/O status information
3.2.2 Scheduling Queues
- Job queue – set of all processes in the system.
- Ready queue – set of all processes residing in main memory, ready and waiting to execute.
- Device queues – set of processes waiting for an I/O device.
- Process migration between the various queues.
3.2.3 Context Switch(上下文切换)
- When CPU switches to another process, the system must save the state of the old process and load the saved state for the new process via a context switch
- Context of a process represented in the PCB
- Context-switch time is overhead; the system does no useful work while switching
- Time dependent on hardware support
3.3.1 Process Creation进程创建
Parent process create children processes, which, in turn create other processes, forming a tree of processes.
Generally, process identified and managed via a process identifier (pid)
Resource sharing:
Parent and children share all resources.
Children share subset of parent’s resources.
Parent and child share no resources.
fork system call creates new process
- int pid = fork();
- 从系统调用 fork 中返回时,两个进程除了返回值 pid 不同外,具有完全一样的用户级上下文。在子进程中,pid 的值为0;父进程中, pid 的值为子进程的进程号。
exec system call used after a fork to replace the process’ memory space with a new program
Producer-Consumer Problem
- unbounded-buffer places no practical limit on the size of the buffer.
- bounded-buffer assumes that there is a fixed buffer size.
Threads
The concept of a process as embodying two characteristics :
- Unit of Resource ownership (资源拥有单位)- process is allocated a virtual address space to hold the process image
- Unit of Dispatching (调度单位)- process is an execution path through one or more programs
- execution may be interleaved with other processes
A thread (or lightweight process) is a basic unit of CPU utilization; it consists of:
- a thread ID
- program counter
- register set
- stack space
Has an execution state (running, ready, etc.);Saves thread context when not running;Has an execution stack;Has some per-thread static; storage for local variables;Has access to the memory and resources of its process,all threads of a process share this。
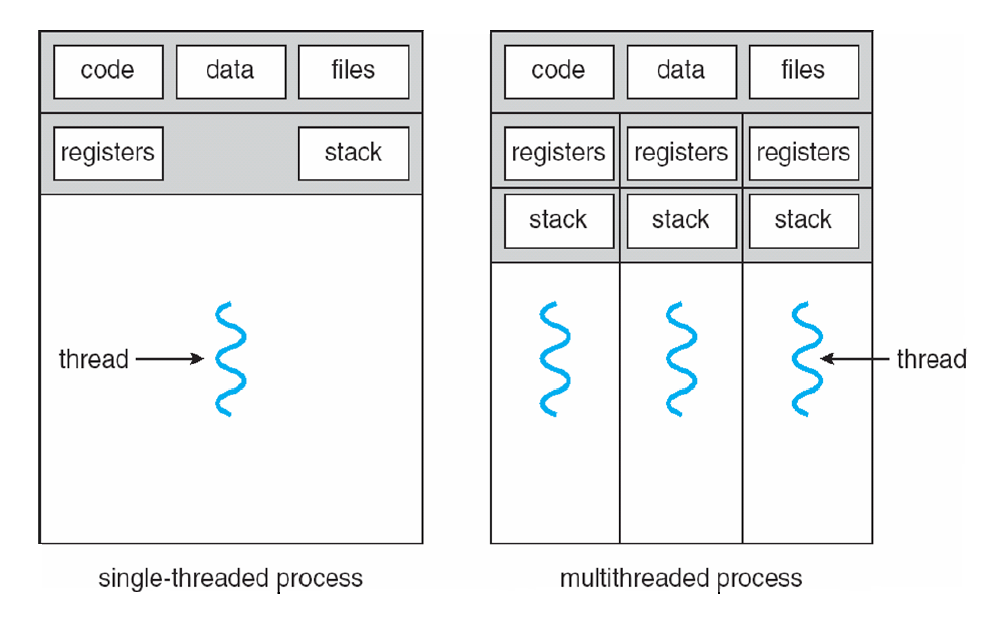
A thread shares with threads belonging to the same process its:
- code section
- data section
- operating-system resources
(Process Have a virtual address space which holds the process image Protected access to processors, other processes, files, and I/O resources)
User Threads(用户级线程)
Thread management done by user-level threads library
- 用户线程的维护由应用进程完成;
- 内核不了解用户线程的存在;
- 用户线程切换不需要内核特权;
- 用户线程调度算法可针对应用优化;
- 一个线程发起系统调用而阻塞,则整个进程在等待。
Three primary thread libraries:
POSIX Pthreads
Win32 threads
Java threads
Kernel Threads (内核级线程)
Supported by the Kernel
- 内核维护进程和线程的上下文信息;
- 线程切换由内核完成;
- 时间片分配给线程,所以多线程的进程获得更多CPU时间;
- 一个线程发起系统调用而阻塞,不会影响其他线程的运行。
Examples
- Windows XP/2000 及以后
- Solaris
- Linux
- POSIX Pthreads
- Mac OS X
CPU scheduling
- Turnaround time周转时间 =完成时间-提交时间
- Average Turnaround time平均周转时间=Σ周转时间/进程数
- Response time响应时间:从进程提出请求到首次被响应(而不是输出结果)的时间段(在分时系统环境下)
- Waiting time等待时间 – 进程在就绪队列中等待的时间总和
- Throughput(吞吐量) – # of processes that complete their execution per time unit
first-come, first served (FCFS)
shortest job first (SJF)
- provably optimal, but difficult to know CPU burst
Highest Response Ratio Next ( HRRN,最高响应比优先)
响应比R = (等待时间 + 要求执行时间) / 要求执行时间
是FCFS和SJF的折衷
general priority scheduling
- starvation, and aging
round-robin (RR)
- for time-sharing, interactive system
- problem: how to select the time quantum?
Multilevel queue
- different algorithms for different classes of processes
Multilevel feedback queue
- allow process to move from one (ready) queue to another
Process Synchronization
Critical-Section Problem
Each process has a code segment, called critical section(临界区), in which the shared data is accessed.
Problem – ensure that when one process is executing in its critical section, no other process is allowed to execute in its critical section.
// TODO
Deadlock
4个必要条件
Mutual exclusion(互斥): only one process at a time can use a resource.
Hold and wait(占有并等待、请求和保持) : a process holding at least one resource is waiting to acquire additional resources held by other processes.请求和保持(Hold and wait)条件:进程已经保持了至少一个资源,但又提出了新的资源要求,而该资源又已被其它进程占有,此时请求进程阻塞,但又对已经获得的其它资源保持不放
No preemption(不可抢占、不剥夺) : a resource can be released only voluntarily by the process holding it, after that process has completed its task.
Circular wait(循环等待): there exists a set {P0, P1, …, Pn} of waiting processes such that P0 is waiting for a resource that is held by P1, P1 is waiting for a resource that is held by P2, …, Pn–1 is waiting for a resource that is held by Pn, and Pn is waiting for a resource that is held by P0.
Resource-Allocation Graph
请求边 分配边
Safety State
Avoidance algorithms
Single instance of a resource type
- Use a resource-allocation graph
Multiple instances of a resource type
- Use the banker’s algorithm
Resource-Allocation Graph Algorithm
- 算法:假设进程Pi申请资源Rj。只有在需求边Pi > Rj 变成分配边 Rj > Pi 而不会导致资源分配图形成环时,才允许申请。
- 用算法循环检测,如果没有环存在,那么资源分配会使系统处于安全状态。如果存在环,资源分配会使系统不安全。进程Pi必须等待。
Detection:
wait-for graph
Banker Algorithm
Main Memory
Contiguous Allocation
- fixed partitioning
- dynamic partition
Paging
Page table is kept in main memory
- Page-table base register (PTBR) points to the page table, x86: cr3
- Page-table length register (PRLR) indicates size of the page table
- In this scheme every data/instruction access requires two memory accesses. One for the page table and one for the data/instruction.
- The two memory access problem can be solved by the use of a special fast-lookup hardware cache called associative memory or translation look-aside buffers (TLBs) (联想寄存器、快表)
- Some TLBs store address-space identifiers (ASIDs) in each TLB entry – uniquely identifies each process to provide address-space protection for that process
Effective Access Time (EAT)
EAT = (t+e) a + ( t + t + e) (1 – a)
Virtual Memory
局部性原理(principle of locality):指程序在执行过程中的一个较短时期,所执行的指令地址和指令的操作数地址,分别局限于一定区域。表现为:
- 时间局部性:一条指令的一次执行和下次执行,一个数据的一次访问和下次访问都集中在一个较短时期内;
- 空间局部性:当前指令和邻近的几条指令,当前访问的数据和邻近的数据都集中在一个较小区域内。
虚拟存储器是具有请求调入功能和置换功能,能仅把进程的一部分装入内存便可运行进程的存储管理系统,它能从逻辑上对内存容量进行扩充的一种虚拟的存储器系统
The effective memory-access time is
(1 – p) x physical-memory-access + p x ( page-fault-overhead + swap-page-out + swap-page-in + restart-overhead )
Page Replacement Algorithms
- First-In-First-Out Algorithm (FIFO,先进先出算法)
- Optimal Algorithm (OPT 最佳页面置换算法)
- Least Recently Used (LRU) Algorithm (最近最久使用算法)
- LRU Approximation Algorithms (近似LRU算法) :
- Additional-Reference-Bits Algorithm
- Second-Chance(clock) Algorithm
- Enhanced Second-Chance Algorithm
- Counting-Base Page Replacement:
- Least Frequently Used Algorithm (LFU最不经常使用算法)
- Most Frequently Used Algorithm (MFU引用最多算法)
- Page Buffering Algorithm(页面缓冲算法)
Buddy
Slab
File System
FAT32磁盘的结构
主引导记录MBR是主引导区的第一个扇区,它由二部分组成:
- 第一部分主引导代码,占据扇区的前446个字节,磁盘标识符(FD 4E F2 14)位于这段代码的未尾。
- 第二部分是分区表,分区表中每个条目有16字节长,分区表最多有4个条目,第一个分区条目从扇区的偏移量位置是0x01BE。
扩展引导记录与主引导记录类同,如该扩展分区未装操作系则第一部分主引导代码为0,标签字也标记一个扩展分区引导区和分区引导区的结束。
PC计算机系统启动时,首先执行的是BIOS引导程序,完成自检,并加载主引导记录和分区表,然后执行主引导记录,由它引导激活分区引导记录,再执行分区引导记录,加载操作系统,最后执行操作系统,配置系统。
IO System
- Polling
- interruption
- Direct memory access
Buffering - store data in memory while transferring between devices,用来保存在两设备之间或在设备和应用程序之间所传输数据的内存区域。
缓冲作用:
- 解决设备速度不匹配
- 解决设备传输块的大小不匹配
- 为了维持拷贝语义“copy semantics”要求
Caching (高速缓存)- fast memory holding copy of data
- 缓冲与高速缓存的差别是缓冲只是保留数据仅有的一个现存拷贝,而高速缓存只是提供了一个驻留在其他地方的数据的一个高速拷贝。
- 高速缓存和缓冲是两个不同的功能,但有时一块内存区域也可以同时用于两个目的。
- 当内核接收到I/O请求时,内核首先检查高速缓存以确定相应文件的内容是否在内存中。如果是,物理磁盘I/O就可以避免或延迟。
SPOOLing(Simultaneous Peripheral Operation On Line)称为假脱机技术。用来保存设备输出的缓冲,这些设备如打印机不能接收交叉的数据流。
操作系统通过截取对打印机的输出来解决这一问题。应用程序的输出先是假脱机到一个独立的磁盘文件上。当应用程序完成打印时,假脱机系统将相应的待送打印机的假脱机文件进行排队
Printing:打印机虽然是独享设备,通过SPOOLing技术,可以将它改造为一台可供多个用户共享的设备。
RAID 0:如果你有n块磁盘,原来只能同时写一块磁盘,写满了再下一块,做了RAID 0之后,n块可以同时写,速度提升很快,但由于没有备份,可靠性很差。n最少为2。
RAID 1:正因为RAID 0太不可靠,所以衍生出了RAID 1。如果你有n块磁盘,把其中n/2块磁盘作为镜像磁盘,在往其中一块磁盘写入数据时,也同时往另一块写数据。坏了其中一块时,镜像磁盘自动顶上,可靠性最佳,但空间利用率太低。n最少为2。
RAID 3:.RAID 3是若你有n块盘,其中1块盘作为校验盘,剩余n-1块盘相当于作RAID 0同时读写,当其中一块盘坏掉时,可以通过校验码还原出坏掉盘的原始数据。这个校验方式比较特别,奇偶检验,1 XOR 0 XOR 1=0,0 XOR 1 XOR 0=1,最后的数据时校验数据,当中间缺了一个数据时,可以通过其他盘的数据和校验数据推算出来。但是这有个问题,由于n-1块盘做了RAID 0,每一次读写都要牵动所有盘来为它服务,而且万一校验盘坏掉就完蛋了。最多允许坏一块盘。n最少为3.
RAID 5:在RAID 3的基础上有所区别,同样是相当于是1块盘的大小作为校验盘,n-1块盘的大小作为数据盘,但校验码分布在各个磁盘中,不是单独的一块磁盘,也就是分布式校验盘,这样做好处多多。最多坏一块盘。n最少为3.
RAID 6:在RAID 5的基础上,又增加了一种校验码,和解方程似的,一种校验码一个方程,最多有两个未知数,也就是最多坏两块盘。
学长的去年题目回忆
70题选择题,每题1分。约15分题目涉及到实验内容。
三道简答题:
- 一个文件系统采用index allocation, 有16个direct index, single/double/triple indirect index各一个,Block size=1024B, block number fits into 4bytes, 计算最大支持的文件大小.
- buddy memory allocation.
- hashed page table, inverted page table.
本文标题:操作系统 复习笔记
文章作者:Han Yang
发布时间:2018-01-21
最后更新:2022-09-06
版权声明:本博客所有文章除特别声明外,均采用 CC BY-NC-SA 3.0 CN 许可协议。转载请注明出处!
分享